Ao pensar sobre o contexto de uma visualização, é fundamental que consigamos nos expressar e entender a relação entre os dados disponíveis e a visualização. Discutimos isso um pouco ao comentar o contexto de uma visualização em outro post, mas como relacionamentos frequentemente são complicados, vamos tentar entrar aqui em mais detalhes sobre essa relação.
Uma visão mais simples
Em um caso simples, essa relação é direta. Veja por exemplo essa visualização feita publicada por Jairo Nicolau no twitter em 2018:
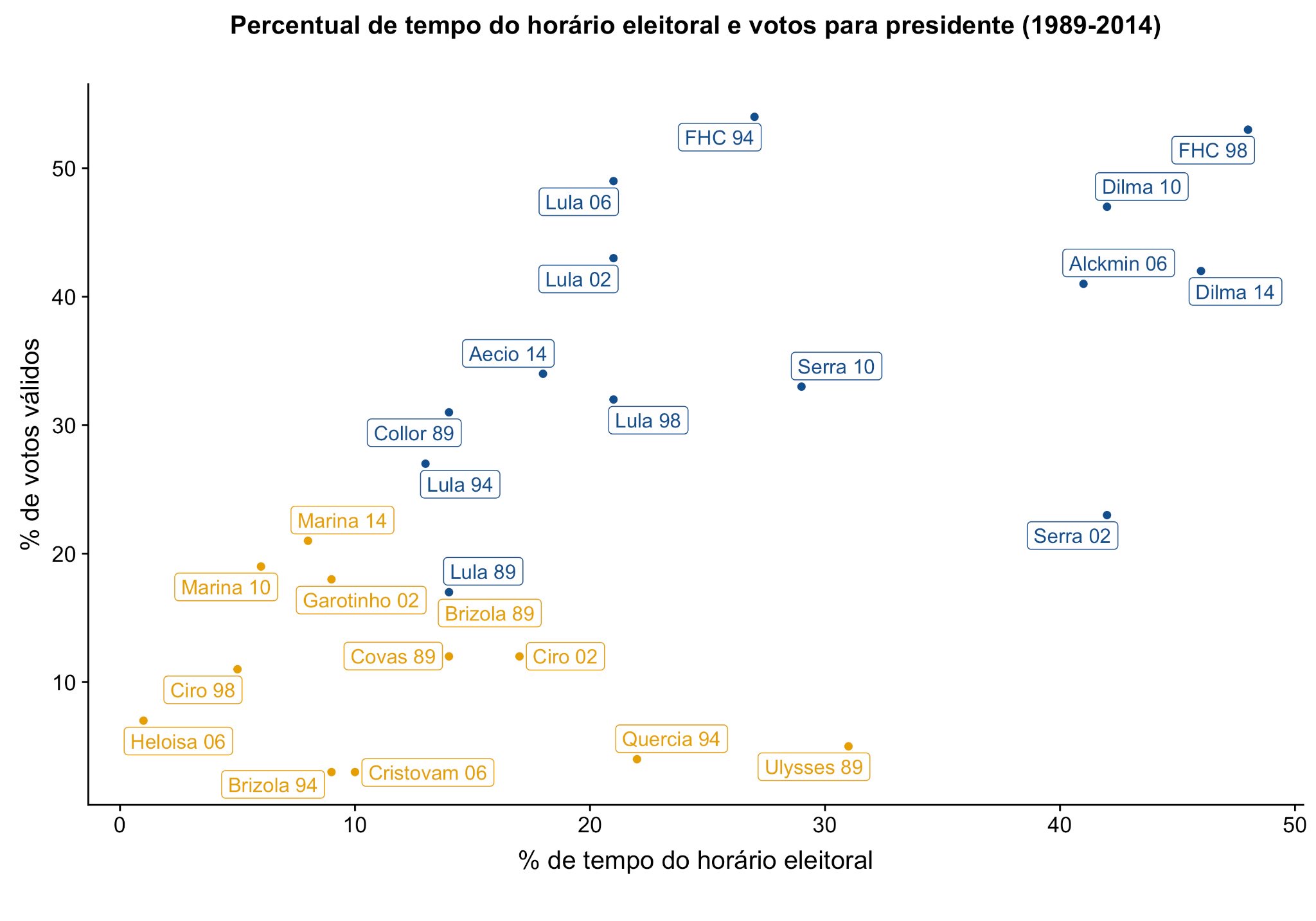
Aqui fica mais ou menos claro que ele provavelmente partiu um conjunto de dados que é uma tabela onde os itens são votações recebidas por candidatos no 1o turno de eleições presidenciais. Os itens têm 5 atributos: nome (nominal/categórico), ano da eleição (ordinal), % de votos válidos (quantitativo), % de tempo do horário eleitoral (quant.) e algo como “foi ao 2o turno?” (nominal, com sim/não).
Se os dados estão assim, é de se imaginar que o trabalho de quem faz o design é decidir como usar esses dados para criar uma visualização que atenda a certas tarefas. Nesse caso, algumas tarefas do domínio do problema são investigar a relação entre tempo de TV e votação recebida e encontrar candidato/as que tiveram um comportamento inesperado. Exemplos de tarefas descritas de modo mais abstrato são identificar correlação entre atributos, identificar grupos de itens com valores de atributos semelhantes (clusters), e encontrar pontos fora da tendência geral da correlação.
O caso mais comum
O mais provável é que os dados não estavam já nesse formato que descrevi acima. O mundo não é um lugar assim tão fácil, e por isso os dados nunca estão no formato que queremos. Ou falando mais sério, é de se imaginar que os dados disponíveis estivessem em um formato mais parecido com nome, ano, turno, tempo de tv, votos recebidos. Esse é um formato mais próximo daquele em que o dado é produzido pelo TSE e que permite mais análises (o dado da seção acima não permite comparar tempos absolutos de TV por exemplo). Além disso, é possível que houvesse dados do 1o e 2o turnos.
Para produzir os dados no formato usado na visualização é preciso partir desses dados disponíveis e aplicar transformações para produzir os dados visualizados. Uma transformação significa aplicar qualquer algoritmo aos dados, mas quase sempre é principalmente usar álgebra relacional nos dados: filtrar itens baseado em atributos (where em SQL), escolher apenas alguns atributos (select) criar novas colunas a partir das que temos (eg. a de % dos votos a partir do total daquele ano), calcular sumários estatísticos como médias, máximos, etc. (group_by + funções em SQL), ou cruzar dados (joins, os melhores).
A razão pela qual estamos discutindo isso aqui é que esse processo de transformação faz parte do trabalho de quem está projetando visualizações a partir de dados. Os dados raramente estarão no formato ideal, e pensar neles apenas no formato inicialmente disponível restringe demais as suas possibilidades. Assim, o fluxo completo que usaremos pra pensar nosso trabalho inclui partir dos dados disponíveis, conceber transformações possíveis ou necessárias e projetar visualizações a partir dos dados disponíveis ou transformados.